在進行長距離的河川探索(如大甲溪、濁水溪)時,我們依賴 ATAK (Android Team Awareness Kit) 作為主要的軌跡記錄工具。然而,在實際作業中遇到了一個痛點:
ATAK 為了效能或訊號不穩,常會將一整天的行程自動切分成多個軌跡檔案 (GPX/KML)。
這造成兩個後續應用的問題:
- 管理困難:一天產生 3-4 個檔案,Day 4 就有三個 GPX (
01:31,04:47,06:12)。 - Data Package 限制:ATAK 的 Data Package 雖然好用,但主要針對靜態圖層 (Points, Shapes),對於「動態軌跡」的打包支援較弱,往往需要手動匯出 GPX。
- Google My Maps 拒收:當我們想把這些高精度的原始軌跡整合到 Google My Maps 分享時,會因為點數過多 (Over 2000 points) 而導致上傳失敗或顯示不全。
🛠️ 解決方案:Python 自動化合併與抽稀
為了不僅將檔案「接起來」,還要能「瘦身」給 Google 吃,我開發了一個 Python 腳本來處理這個標準作業程序。
步驟一:處理 Namespace 陷阱
ATAK 輸出的 GPX 檔案,其 XML Namespace 有時會帶有尾端斜線(.../GPX/1/1/),這會導致標準的 Python xml.etree.ElementTree 解析失敗。
解法:寫一個 Helper Function strip_ns(),不管 Namespace 長怎樣,只認標籤名稱(如 trkpt),這樣最穩健。
步驟二:合併 (Merge)
將多個 GPX 檔案的時間軸串聯起來。雖然 GPX 支援 <trkseg> (多段),但為了讓 Google My Maps 將其視為「同一條路線」,我選擇將所有點合併到同一個 Segment 中。這樣在地圖上就是一條連續的線,視覺效果最好。
步驟三:抽稀 (Downsample)
這是最關鍵的一步。原始的高精度軌跡(Day 4 有 6,586 點)遠超 Google My Maps 的 2,000 點限制。
演算法:
- 設定目標點數
TARGET_POINTS = 1900(留點緩衝)。 - 計算採樣率:
Step = Total / Target(例如每 4 點取 1 點)。 - Python List Slicing:
sampled_points = all_points[::step]。 - 強制保留終點:確保最後一個點一定被收錄,避免軌跡被「截斷」。
💻 程式碼實作
# 核心抽稀邏輯
TARGET_POINTS = 1900
step = math.ceil(total_points / TARGET_POINTS)
sampled_points = all_points[::step]
# 強制保留終點
if all_points[-1] not in sampled_points:
sampled_points.append(all_points[-1])
🎉 成果
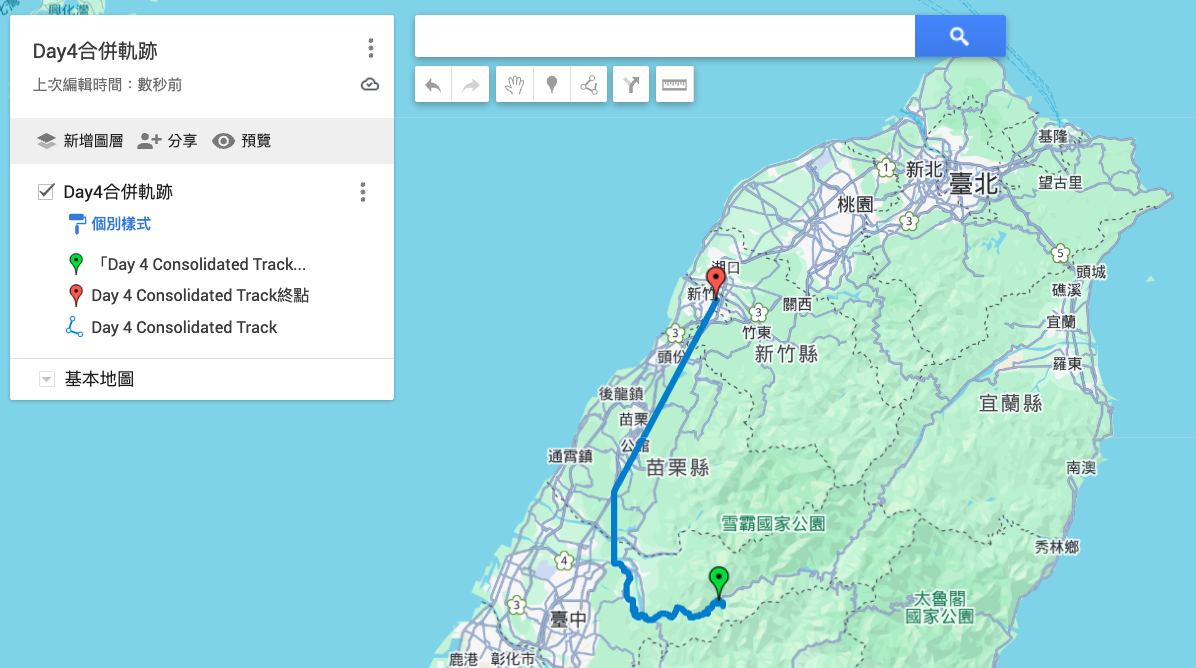
- 原始狀態:3 個檔案,共 6,586 點 -> Google My Maps ❌ 失敗。
- 處理後:1 個檔案 (
merged_day4_lite.gpx),共 1,648 點 -> Google My Maps ✅ 完美顯示。
這個流程現在已經腳本化,未來每次探索結束後,只要一鍵執行就能產出適合分享與封存的軌跡檔案。
附件下載
AI 協作宣告:本文初稿由 AI 助手(Antigravity)協助生成,並由人類作者進行核實與修訂。文中使用的 Python 腳本為人類與 AI 透過 Pair Programming 共同開發之成果。